音声認識システムを使うとき、無音部分までデータを送るのは料金だったりリソースの無駄になりがち。
それに、無音や雑音を音声認識させると、何かと変な結果が返ってきがち。
そこで前々から気になっていたのがVAD(Voice Activity Detection、発話区間検出)。
中でもSilero VADは精度が高いらしいけど、
・ストリーミングで発話区間を検出して
・ソースコードがコンパクトで
・全体の音声データをWAV形式で保存して
・発話部分だけを切り出して、これもWAV形式で保存して
・発話ごとのラベル情報を記録して
といったサンプルが見つからなかったので、自分で作ってみました。
もちろん、ChatGPTの力を存分に借りて。
処理結果
出力結果をAudacity(音声データ編集や可視化ができるオープンソースのツール)で見ると、こんな感じ。
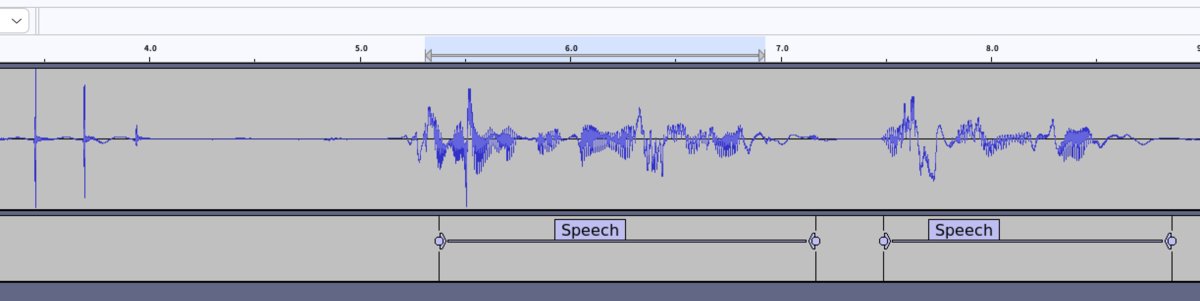
試しに使った限りでは、かなりいい感じに識別!(主観)
(何もない状態からイキナリ「発話だ!」とは識別できないので、どうしても波形よりもちょっと遅れたタイミングで発話が検出されています。)
確認環境
デスクトップPC
Ubuntu 22.04
Python 3.10
インストール
pip install numpy torch torchaudio pyaudio
ソースコード
import torch import numpy as np import wave import pyaudio import datetime from typing import List, Dict, Any # 定数定義 CHUNK_SIZE = 512 CHANNELS = 1 RATE = 16000 SAMPLE_WIDTH = 2 # 16bit = 2 bytes # ベースとなる日時文字列 BASE_TIME_STR = datetime.datetime.now().strftime("%Y%m%d_%H%M%S") # 出力ファイルパスやフォーマットを定数で定義 FULL_AUDIO_PATH = f"{BASE_TIME_STR}_audio_full.wav" PARTIAL_AUDIO_FORMAT = f"{BASE_TIME_STR}_audio_{{time}}.wav" VAD_TEXT_PATH = f"{BASE_TIME_STR}_vad.txt" class AudioRecorder: def __init__(self): # マイクデバイスの設定 self.rate = RATE self.chunk_size = CHUNK_SIZE self.channels = CHANNELS self.py_audio = pyaudio.PyAudio() self.stream = None def get_default_input_device_info(self) -> str: device_info = self.py_audio.get_default_input_device_info() return f"使用中のマイクデバイス: {device_info['name']} (デバイス ID: {device_info['index']})" def open_stream(self) -> None: # マイクからの入力ストリームを開始 self.stream = self.py_audio.open(format=pyaudio.paInt16, channels=self.channels, rate=self.rate, input=True, frames_per_buffer=self.chunk_size) def close_stream(self) -> None: # ストリームとPyAudioインスタンスを閉じてリソース解放 if self.stream is not None: self.stream.stop_stream() self.stream.close() self.py_audio.terminate() def read_chunk(self) -> bytes: # 一定サイズ(chunk_size)の音声データを取得 return self.stream.read(self.chunk_size) class SileroVADProcessor: def __init__(self): # Silero VADモデルをロード self.model, self.utils = torch.hub.load( repo_or_dir='snakers4/silero-vad', model='silero_vad', force_reload=False ) (self.get_speech_timestamps, self.save_audio, self.read_audio, self.VADIterator, self.collect_chunks) = self.utils # ストリーム処理用のVADIteratorを生成 self.vad_iterator = self.VADIterator(self.model) def process(self, data: bytes) -> Dict[str, Any]: # VAD処理を行う # PyAudioで取得した16bit整数値データをfloat32(-1.0〜1.0)に正規化 data_np = np.frombuffer(data, dtype=np.int16) audio_float32 = torch.from_numpy(data_np.copy()).float() / 32768.0 # vad_iteratorを用いて現在のフレームで音声開始・終了を判定する return self.vad_iterator(audio_float32, return_seconds=True) class FullAudioWriter: def __init__(self, file_path: str): self.file_path = file_path self.full_wav_handle = None def open(self) -> None: # WAVファイルを"書き込みモード"で開き、チャンネル数、サンプル幅、サンプリングレートを設定 self.full_wav_handle = wave.open(self.file_path, 'wb') self.full_wav_handle.setnchannels(CHANNELS) self.full_wav_handle.setsampwidth(SAMPLE_WIDTH) self.full_wav_handle.setframerate(RATE) def write(self, data: bytes) -> None: if self.full_wav_handle: self.full_wav_handle.writeframes(data) def close(self) -> None: if self.full_wav_handle: self.full_wav_handle.close() self.full_wav_handle = None class PartialAudioWriter: def __init__(self, file_format: str): self.file_format = file_format def save(self, frames: List[bytes], start_time: float) -> str: # 発話開始時刻を用いてファイル名を決定(小数点をアンダースコアに置き換える) sanitized_time = str(start_time).replace('.', '_') output_wav_file = self.file_format.format(time=sanitized_time) with wave.open(output_wav_file, 'wb') as wf: wf.setnchannels(CHANNELS) wf.setsampwidth(SAMPLE_WIDTH) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) return output_wav_file class VADTextReporter: def __init__(self, vad_text_file_path: str): self.file_path = vad_text_file_path self.file_handle = open(self.file_path, 'a', encoding='utf-8') def write_segment(self, start: float, end: float, label: str) -> None: self.file_handle.write(f"{start:.2f}\t{end:.2f}\t{label}\n") def close(self) -> None: if self.file_handle: self.file_handle.close() self.file_handle = None class VoiceActivityDetector: def __init__(self, debug: bool, full_audio_file_path: str, partial_audio_file_format: str, vad_text_file_path: str): self.debug = debug self.audio_recorder = AudioRecorder() self.vad_processor = SileroVADProcessor() if self.debug: self.full_audio_writer = FullAudioWriter(full_audio_file_path) self.full_audio_writer.open() print(f"全音声の出力開始: path={full_audio_file_path}") self.partial_audio_writer = PartialAudioWriter(partial_audio_file_format) self.vad_text_reporter = VADTextReporter(vad_text_file_path) print(f"VAD結果の出力開始: path={vad_text_file_path}") else: # debug=Falseの場合、これらはNoneのまま self.full_audio_writer = None self.partial_audio_writer = None self.vad_text_reporter = None def print_device_info(self) -> None: # 現在使用中のマイクデバイス情報を表示 print(self.audio_recorder.get_default_input_device_info()) def record_audio(self) -> None: frames = [] # 全チャンクデータを保持するリスト current_time = 0.0 # 現在の録音経過時間(秒) processed_size = 0 # 処理済みオーディオバイト数 speech_buffer = [] # 発話区間のオーディオデータを保持するバッファ start_time = None # 発話開始時刻 is_speech = False # 現在、発話中であるかどうか # マイク入力ストリームを開始 self.audio_recorder.open_stream() print("マイク音声入力中... (Ctrl+C で終了)") try: while True: data = self.audio_recorder.read_chunk() # debug時のみ音声記録 if self.full_audio_writer: self.full_audio_writer.write(data) # 現在のチャンクに対してVAD処理を行う vad_dic = self.vad_processor.process(data) # VAD結果に"start"が含まれていれば、発話開始 if vad_dic and "start" in vad_dic: start_time = current_time is_speech = True print(f"発話検出! start_time={start_time:.2f}") # 発話開始時は、検出の遅れを補正するため、直前0.25秒分のデータも発話区間に含める back_buffer_count = int(0.25 * RATE / CHUNK_SIZE) # framesリストの末尾からback_buffer_count分を取り出し、speech_bufferに蓄積 speech_buffer = frames[-back_buffer_count:] if back_buffer_count > 0 else [] # VAD結果に"end"が含まれていれば、発話終了 elif vad_dic and "end" in vad_dic: end_time = current_time is_speech = False print(f"発話検出終了 start_time={start_time:.2f}, end_time={end_time:.2f}") # debug時のみ、発話区間のWAVファイル出力とテキスト追記 if self.partial_audio_writer: saved_path = self.partial_audio_writer.save(speech_buffer, start_time) print(f"発話音声を保存しました: {saved_path}") if self.vad_text_reporter: self.vad_text_reporter.write_segment(start_time, end_time, "Speech") # 発話バッファをクリア speech_buffer = [] # 常にframesに現在のチャンクを追加 frames.append(data) # 発話中であればspeech_bufferにも追加 if is_speech: speech_buffer.append(data) # 処理済みデータサイズを更新し、current_timeを計算 processed_size += len(data) # 1サンプル=2バイト(s16le)なので、秒数 = (バイト数 / サンプリングレート / サンプル幅) current_time = processed_size / RATE / SAMPLE_WIDTH except KeyboardInterrupt: print("\n音声検出を終了しました。") finally: self.audio_recorder.close_stream() # debug時はfull_audio_writer, vad_text_reporterをclose(print不要) if self.full_audio_writer: self.full_audio_writer.close() print(f"全音声の出力終了") if self.vad_text_reporter: self.vad_text_reporter.close() print(f"VAD結果の出力終了") if __name__ == "__main__": # debug=Trueで全音声、部分音声、VAD結果テキスト出力を有効化 vad = VoiceActivityDetector( debug=True, full_audio_file_path=FULL_AUDIO_PATH, partial_audio_file_format=PARTIAL_AUDIO_FORMAT, vad_text_file_path=VAD_TEXT_PATH ) vad.print_device_info() vad.record_audio()