今回試したのは、ウェイクワード検出。
別名、ホットワード検出とか、キーワード検出とか、キーワードスポッティング。
このウェイクワード検出を使うと、「オッケー グーグル」とかや「アレクサ」みたいなキーワードを喋ったかどうか判断できるようになります。
過去にも一度、オープンソースのウェイクワード検出を試してみたことがあったけど、そのとき使ったライブラリは判定結果がイマイチでした。
今回、openWakeWord というライブラリを使っている記事を見かけ、公式ページで紹介されている検出精度も良かったので、期待して使ってみました。
処理結果
出力結果をAudacity(音声データ編集や可視化ができるオープンソースのツール)で見ると、こんな感じ。
ウェイクワードを発話した直後に検出してくれます。
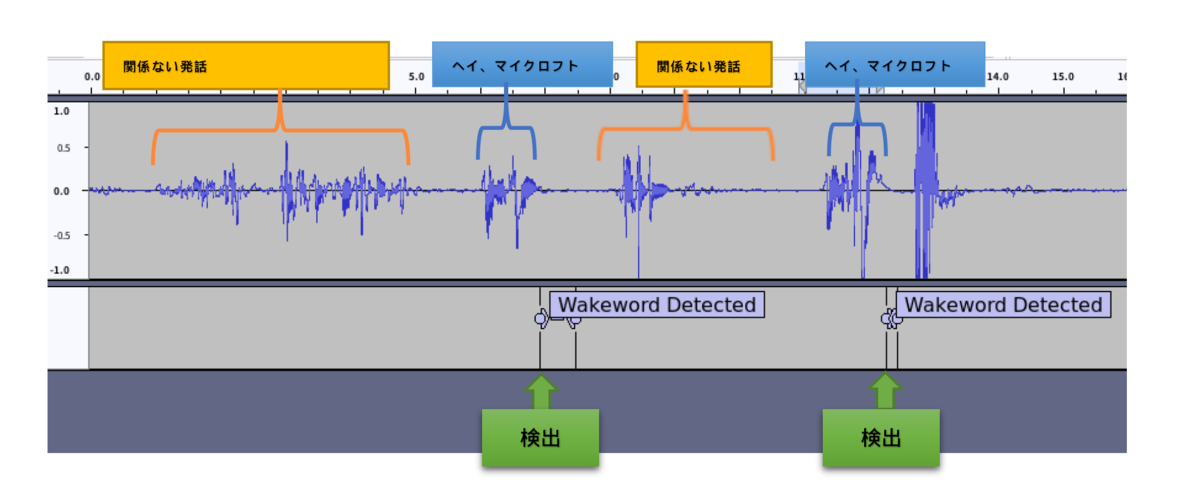
英語用「hey mycroft」検出モデルを使ったのですが、 日本語で呼びかけても、かなりいい感じに検出してくれました(主観)
特徴
- ウェイクワード検出精度が高い
- 関係ない音に対して誤検出が少ない
- 低負荷で動作
- 学習済みモデルが複数提供されている
- 複数モデルの並列検出が可能
- 新しいモデルのトレーニングもサポート(未確認。サポート言語は英語)
- オープンソース
- ライセンスはApache 2.0
こうやって並べて書いてみると、いいことづくめですね。
用意されている学習済みモデル
用意されている学習済みモデルは以下の通り。
言語は英語。
なんだけど、アレクサとかhey mycroftとか、日本語でもいい感じに検出してくれました。
| モデル | 発話するべきキーワード |
|---|---|
| alexa | "alexa" |
| hey mycroft | "hey mycroft" |
| hey jarvis | "hey jarvis" |
| hey rhasspy | "hey rhasspy" |
| current weather | "what's the weather" |
| timers | "set a 10 minute timer" |
確認環境
インストール
NumPy 2.xではエラーが出たので、2未満のバージョンを指定してインストールしました。
pip install openwakeword pyaudio "numpy<2"
ソースコード
公式のサンプルコードが十分コンパクトでわかりやすく、複数のキーワードを並列で検出できるようになっています。
なので別に自分でサンプルを書く必要はないかもしれませんが、音声データと検出結果を出力してみたかったので、自分で書いてみました。
「hey mycroft」というキーワードを検出する例です。
import os import openwakeword import pyaudio import numpy as np import wave from datetime import datetime from openwakeword.model import Model # 定数定義 FORMAT = pyaudio.paInt16 # 音声フォーマット: 16bit整数 CHANNELS = 1 # モノラル音声 RATE = 16000 # サンプリングレート (16kHz) CHUNK_SIZE = 512 # 一度に読み込むフレームサイズ WAKEWORD_THRESHOLD = 0.5 # ウェイクワード検出の閾値 class AudioRecorder: def __init__(self): self.rate = RATE self.chunk_size = CHUNK_SIZE self.channels = CHANNELS self.format = FORMAT self.py_audio = pyaudio.PyAudio() # PyAudioのインスタンス self.stream = None # マイク入力ストリーム def open_stream(self) -> None: self.stream = self.py_audio.open(format=self.format, channels=self.channels, rate=self.rate, input=True, frames_per_buffer=self.chunk_size) def close_stream(self) -> None: if self.stream is not None: self.stream.stop_stream() self.stream.close() self.py_audio.terminate() def read_chunk(self) -> bytes: return self.stream.read(self.chunk_size) class WakewordProcessor: def __init__(self, model_path: str): # OpenWakeWordモデルをロード self.oww_model = Model(wakeword_models=[model_path]) def predict(self, audio_data: bytes) -> float: # 音声データをNumPy配列に変換(16bit整数型) audio_np = np.frombuffer(audio_data, dtype=np.int16) self.oww_model.predict(audio_np) # OpenWakeWordモデルで推論 # 直近のウェイクワード検出スコアを取得 for scores in self.oww_model.prediction_buffer.values(): return scores[-1] # 最後のスコアを返す return 0.0 # デフォルト値 class FullAudioWriter: def __init__(self, file_path: str): self.file_path = file_path self.wav_file = wave.open(self.file_path, 'wb') self.wav_file.setnchannels(CHANNELS) self.wav_file.setsampwidth(pyaudio.PyAudio().get_sample_size(FORMAT)) self.wav_file.setframerate(RATE) def write(self, data: bytes): self.wav_file.writeframes(data) def close(self): self.wav_file.close() class WakewordTextReporter: def __init__(self, file_path: str): self.file_path = file_path def write_segment(self, start_time: float, end_time: float): with open(self.file_path, mode='a', encoding='utf-8') as f: f.write(f"{start_time:.2f}\t{end_time:.2f}\tWakeword Detected\n") class WakewordDetector: def __init__(self, model_name: str, model_directory: str, debug: bool = False): # モデルのダウンロード(動作に必要な基本的なモデル用) openwakeword.utils.download_models() # 使用するウェイクワード用モデルを指定するために、上記とは別にモデルをダウンロード self.model_directory = model_directory openwakeword.utils.download_models(target_directory=self.model_directory) self.model_path = os.path.join(self.model_directory, model_name) # タイムスタンプ付きファイル名 timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") self.full_audio_file = f"{timestamp}_full_audio.wav" self.text_file = f"{timestamp}_wakeword.txt" # 各種オブジェクト初期化 self.audio_recorder = AudioRecorder() self.wakeword_processor = WakewordProcessor(self.model_path) # デバッグモードでのみ出力関連のオブジェクトを初期化 if debug: self.full_audio_writer = FullAudioWriter(self.full_audio_file) self.text_reporter = WakewordTextReporter(self.text_file) else: self.full_audio_writer = None self.text_reporter = None # 状態管理用変数 self.is_detecting = False # 検出中かどうか self.start_time = 0.0 # 発話開始時刻 self.current_time = 0.0 # 現在の録音時間 self.frame_duration = CHUNK_SIZE / RATE # 1フレームあたりの時間 def listen_for_wakeword(self): print("Listening for wakewords... (Press Ctrl+C to stop)") self.audio_recorder.open_stream() try: while True: # 音声データを取得 audio_data = self.audio_recorder.read_chunk() # ウェイクワードの検出スコアを計算 score = self.wakeword_processor.predict(audio_data) # ウェイクワード検出開始判定 if score > WAKEWORD_THRESHOLD and not self.is_detecting: self.is_detecting = True self.start_time = self.current_time print("Wakeword Detection Started!") # ウェイクワード検出終了判定 if score <= WAKEWORD_THRESHOLD and self.is_detecting: self.is_detecting = False end_time = self.current_time print("Wakeword Detection Ended!") # 結果をテキストに記録(デバッグモード時のみ) if self.text_reporter: self.text_reporter.write_segment(self.start_time, end_time) # 全音声データをWAVファイルに保存(デバッグモード時のみ) if self.full_audio_writer: self.full_audio_writer.write(audio_data) # 現在時刻を更新 self.current_time += self.frame_duration except KeyboardInterrupt: print("\nStopped wakeword detection.") finally: self.cleanup() def cleanup(self): self.audio_recorder.close_stream() if self.full_audio_writer: self.full_audio_writer.close() print(f"Full audio saved to: {self.full_audio_file}") if self.text_reporter: print(f"Wakeword text log saved to: {self.text_file}") def main(): script_dir = os.path.dirname(os.path.abspath(__file__)) model_directory = os.path.join(script_dir, "models") model_name = "hey_mycroft_v0.1.tflite" # デバッグモードを有効化(debug=True) detector = WakewordDetector(model_name=model_name, model_directory=model_directory, debug=True) detector.listen_for_wakeword() if __name__ == "__main__": main()